今天要延續昨天專題的內容,一樣是來自台科大的學長,開始感覺到未來訓練模型的步驟了XD
此APP能夠讓使用者唸出特定文字後,便會告訴你有哪些構音需要矯正。
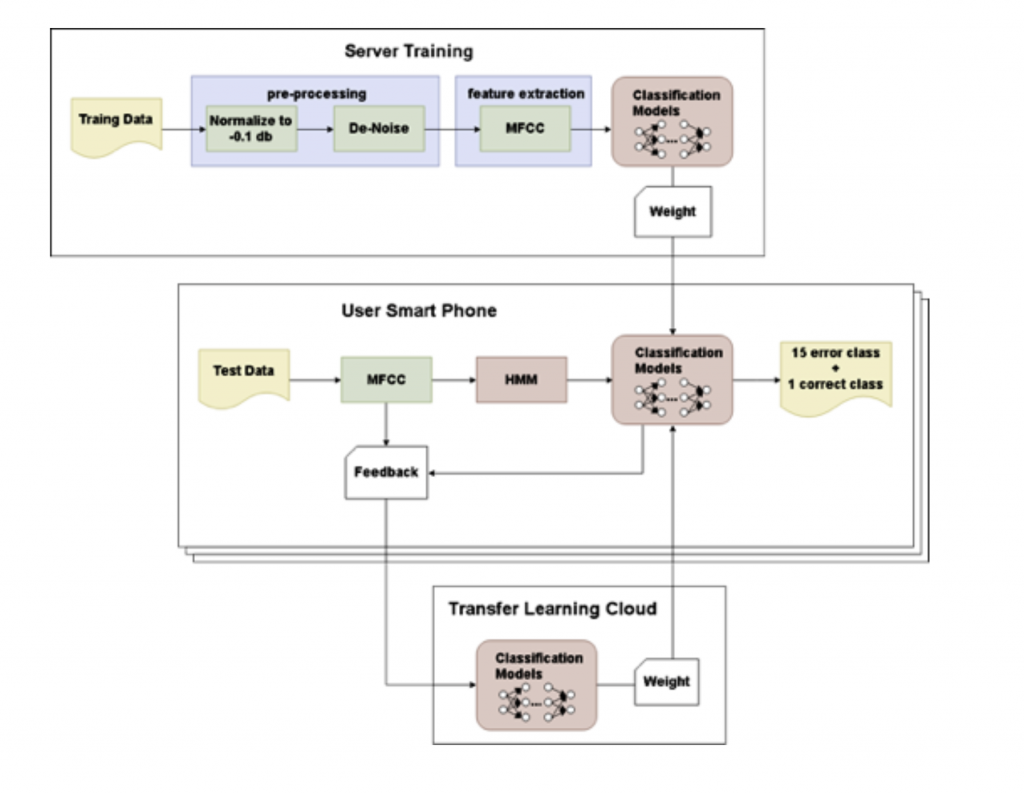
進行語音矯正與辨識需要大量蒐集資料,目前找了 46 位發音正常的人來模擬 15 種構音錯誤及正確構音錄製音檔,而發音正確與錯誤比例大約1:3.3累積資料量總共 7.75 小時
(光是要把資料庫建立起來就是個困難點,而且要把整個流程都想好才可以下手,感覺很辛苦QwQ
使資料更多元、防止過度擬合,我們將數據增強、所有音檔分別進行音調位移 (pitch shift)1,2,-1,-2 。讓資料量擴增五倍,資料量總共 38.75 小時。
做這個擴增的原因除了可以讓資料量變得更多之外,可以把一些不想在training的時候便是錯誤的變因加進去,讓辨識能力增加。除了pitch shift以外還可以加上一些白噪音確保訓練出來的模型可以過濾無意義的資料。
(一)、音量標準化
- 為了使音檔音量一致,我們將音量標準化至-0.1db。
(二)、去雜音
- 為減少雜訊的干擾,我們將音檔進行簡易降造處理,可將音檔中恆定的電磁雜音或是環境噪音濾除。
這感覺和資料擴增相反,把一些模型中不需要辨識的資訊在丟進去模型train之前就去除掉不必要辨識的變因,可以讓模型更有效率。
(當我寫到一半想要找資料時看到了這個寫的完整很多OuO
他們在訓練模型的時候用到了三種不同的方法:
這三個方法我之後會再詳細說明。


 iThome鐵人賽
iThome鐵人賽